Abstract
In search of the best open source coding LLM, Gwen2.5 Coder is a force that cannot be ignored. But what makes Gwen2.5-Coder so good? In this post we make a thorough overview of its sibling model Gwen2.5, touch on Gwen2 a bit and uncover the secret sauce that gives Gwen2.5-Coder its power.
Gwen2.5
Let’s start with the differences between 2.5 and 2:
- Data: Gwen2.5 is pretrained on 18T tokens instead of 7T with main focus on math, coding and knowledge (arxiv, textbooks,…).
- Output Tokens: Gwen2.5 can generate up to 8K tokens compared to 2K.
- Post training: Gwen2.5 was aligned on 1M instruction data with Supervised Fine Tuning (SFT), Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO, this was developed by the DeepSeek team and used in their v3 model). Gwen2 only used SFT and DPO.
- Control tokens: Gwen2.5 has 22 control tokens, where Gwen2 only 3, why is this important? As we will progress we are going to see that these control tokens are used to introduce other pretraining objectives than classical next token prediction, having other pretraining approaches kind of emulates the behaviour of UL2 by T5.
- Model differences: These are extremely minor. Gwen2.5 has QVK bias, Gwen2 does not. Gwen2 has an MOE variant Gwen2.5 does not. There is also slight variation in the number of weights with Gwen2.5 introducing a 32B variant.
Model
The model is very much a standard Transformer++ architecture with:
- Grouped Query Attention
- SwiGLU Activation
- RoPE + Yarn (this is only for context extension)
- RMSNorm
- KVQ Bias
KVQ Bias
Not too fancy, we just add an extra term to the linear projections;
Q = input @ W_q + b_q
K = input @ W_k + b_k
V = input @ W_v + b_v
- is the appropriate bias term
Dual Chunk Attention
This sounds fancy, but for long context input we split the input into chunks so we can process them chunk by chunk.
Tokenizer
A traditional Byte Pair Tokenizer (BPE), exactly the same as used by Gwen2 making the total vocabulary of 151,643 tokens.
Pretraining
We are slowly entering the meat of Gwen2.5, and that is data! As is the trend, it heavily relies on synthetic data which was generated by Gwen2, (Gwen2 already heavily used synthetic data produced by previous version Gwen1.5), this is pretty much standard these days, with Phi4 taking it to the next level (Overall we can view Phi4 as a distilled down version of GPT4).
Strategic Mixture of Data
Researchers realize that some data domains are over-represented like e-commerce, social media and entertainment, however these are usually of lower quality. On the other hand technology, science and academic research is under-represented, but they are in general higher quality and provide more value. Because of this we up-sample the high quality domains and down-sample low quality ones.
Long Context
We start with a context length of 4096 tokens, which we extend to 32,768. The special Gwen2.5 Turbo variant available through the GwenAPI can handle up to 1M tokens, which showcases the flexibility of Gwen!
Post Training
I read a lot of research papers about various language models lately and there is an overall pattern followed by most. We start with supervised finetuning, this gives general instruction following capabilities that is followed by model alignment done by some sort of reinforced learning.
Supervised Fine Tuning (SFT)
SFT with over 1 million examples enhances Gwen2.5 in the following critical areas:
Long-sequence Generation
Gwen2.5 is capable of generating sequences up to 8,192 tokens, however the typical response is only 2000 tokens long. To get long-response dataset we use back-translation (or instruction reversal), thus we find a long form answer and we generate the instruction for it.
Mathematics
Here we take the Chain of Thought (CoT) pretraining data used for Gwen2.5-Math.
Coding
As for math we take the instruction following dataset (this we will explain in depth) that was used to pretrain Gwen2.5-Coder.
Instruction-following
To ensure that instruction following is correct we validate it by generating both the instruction and verification (synthetic data is just everywhere). This could ensure that the models does what is asked to.
Structured Data Understanding
This contains tabular-question answering, fact verification, structural understanding and complex tasks involving structured and semi-structured data. For these types of data we do CoT reasoning since it vastly enhances to infer information from structured data.
Logical Reasoning
To enhance the reasoning capacity it is finetuned on 70k reasoning queries spanning different domains like: multiple-choice answers, true/false questions, open ended questions. Logical reasoning is done in different styles from deductive reasoning, inductive generalization, analogical reasoning, causal and statistical reasoning. Again this is synthetic data that was interactively created, refined and filtered to contain only correct answers with valid reasoning process.
Cross-Lingual Transfer
The model should be able to work with low-resource languages, because of this we take instruction from high-resource languages (English, Chinese) and translate them into low-resource ones. The translation is followed with a comprehensive verification process ensuring that the logical and stylistic nuances are retained from the original text.
Robust System Instruction
This involves tuning the model on different system prompts, with the goal to ensure robustness to it.
Response Filtering
With a dedicated critique model and multi-agent collaborative scoring system to ensure that only correct responses are retained.
Summary on SFT
There is a lot said between the lines, but it should be obvious that the SFT data is mostly made of synthetic data and the authors went a long way to ensure the quality of this data.
Direct Preference Optimization (DPO)
This is an offline (since we can prepare the feedback signals beforehand) Reinforced Learning variant, this gives the advantage that we can evaluate the results without a reward model (code compiles, math problem has correct answer, etc). This dataset involves 150k training samples, and the review process was automated but also with some human overview.
Group Relative Policy Optimization (GRPO)
This method was pioneered by the DeepSeek team, and it is an extension (simplification) of Proximal Policy Optimization (PPO). PPO and GPO are online RL methods, this means we need a reward model. First obtaining a reward model is not cheap, but using it as a feedback model gives a substantial resource overhead. In PPO we score with the reward model each time we generate a new model, and we optimize for each query. In GRPO we score the reward across a group of outputs. How this works is that given a query Gwen2.5 samples multiple outputs each in different group. Groups are then passed to the reward model and we maximize the average reward across the whole group, grouping and averaging leads to lower utilization of the reward model which saves a lot of compute.
Bit about DeepSeek
DeepSeekV3 was released at the end of 2024, and they use this method extensively, which led to substantial cost savings enabling the DeepSeek team to train a model with GPT4-like performance but for a fraction of the cost.
Knowledge Check
Loading...
Loading...
Gwen2.5-Coder
I went in quite depth on the base Gwen2.5 model, by now it should be semi-obvious why. Most of the performance of Gwen2.5 comes from high quality data and synthetic data, where the authors went a huge distance to ensure top-notch quality. Gwen2.5-Coder builds up on this foundation (it uses a bit different type of data) of high quality, synthetic data, generated in an agenting way with extremely high level of quality assurance. So without further ado let’s look into Gwen2.5-Coder.
Data
The pretraining data is made out of 5.5T tokens which consists of:
- Github, scraped public repositories up to February 2024 consisting of total 92 Programming Languages.
- Common Crawl, this is the popular C4 dataset, however heavily filtered only for code-related documentation, tutorials blogs.
- Synthetic Data, which was created in an agenting way, and we will go more in depth later, by leveraging previous Gwen1.5-Coder!
- Math, multiple research suggests that pretraining model on CoT style Math reasoning helps in Coding tasks as well (and vice versa), because of this the authors include the pretraining corpus of Gwen-2.5-Math.
- Text Data, since we want the model to have general language capabilities we take the high-quality pretraining data from the Gwen2.5 corpus.
Mix-ratio
This is very little discussed in other research, but we have multiple different types of data but what ratio we use? Researchers used:
- 70% code
- 20% text
- 10% math
There is also ablation study on different mixtures, but this yielded the best outcomes.

Control Tokens
I already mentioned before Gwen2.5 had 32 control tokens, for software engineering there are 3 groups of control tokens that are useful for us:

- Fill in the middle, what is fill in the middle and why do we need a special token? Most software engineering tasks involve code that is already there and the goal of a software-engineer is to modify add functionality to it. Causal Language models are trained always on next-token prediction, thus making them good at adding text to the end. You can probably see that next-token prediction is not necessarily natural for software-engineering. With Fill-in-the-middle token, we try to force the model to pay attention to gaps in the provided context, and figure out and generate what is missing, not create something new.
- File, most software projects consist of multiple source files, thus it is natural to include multiple files inside the context of the LLM.
- Repository, this just extends the idea introduced in the File group tokens to multiple repositories.
As we are going to see later in the pretraining policy where I give examples of the actual control tokens, these groups are mixed together but the concepts remain the same.
Remarks
Gwen2.5-Coder has the maximum context length of 128k tokens, having repository level control tokens is nice, however it is too contained to work with huge codebases, and there are a lot of issues with long-context transformer models, making it extremely unlikely that they could in future be able to process multiple repositories, not to mention multiple repositories.
Training Policy
I already suggested how LLMs are pretrained, and that it does not necessarily translate into the way how code is written. Introduction of special control tokens enables a slight modification of the pretraining objectives. Why slight? First we will still generate token by token in a causal matter, that is conditioned on previously seen tokens, however we will force the model to leverage the context slightly differently.
Overall we can split the training policy in 3 parts: file-level pretraining, repo-level pretraining and instruction tuning.

File Level Pretraining
Here we pretrain on max sequence length of 8192 tokens and we have 2 objectives:
- Next token prediction
- Fill in the middle
This is the format for the fill in the middle instruction template:
<|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_mid}<|endoftext|>
Repo-Level Pretraining
Context is extended from 8k to 32,768 tokens, with it also the frequency of RoPE (with YARN we can extend up to 128K tokens). We leverage 300B tokens of high quality long-context data with the same pretraining objectives as in file-level pretraining. Here is the instruction template:
<|repo_name|>{repo_name}
<|file_sep|>{file_path1}
{file_content1}
<|file_sep|>{file_path2}
{file_content2}
<|file_sep|>{file_path3}
<|fim_prefix|>{code_pre}<|fim_suffix|>{code_suf}<|fim_middle|>{code_fim}<|endoftext|>
Back to Fill-in-the-Middle
How do we create the fill-in-the-middle data? The solution is surprisingly simple, we parse the code snippet with tree-sitter and we remove certain parts of the code and replace them with the appropriate tokens.
Post-Training
Here we are going to introduce the multi-agent approach to generate proper synthetic data that is later used to align Gwen2.5-Coder, but before we do that let’s look at less hyped approaches to align the model:
- Programming Language Identification: we provide a code snippet and goal of the LLM is to tell what kind of programming language was used.
- Github Instruction Synthesis: this is an example of instruction reversal approach, where we take a code snippet up to 1024 tokens and ask to generate instruction that could have generated it.
Multilingual Code Instruction Multi-Agent System
This is a super hyped name which deserves the hype, and it made me realize that coding is really something that will be automated to quite a high degree. Anyway the main goal of this multi-agent system is to synthesize instructions, mainly for low resource programming languages. Here is the breakdown of the individual parts of the agent system:
- Language Specific Intelligent Agents, each dedicated to specific programming language, each initialized from language specific curated code snippets.
- Collaborative Discussion Protocol, where multiple agents engage in structured dialogue to formulate new instructions and solutions.
- Adaptive Memory, each agent stores a generation history to avoid generating similar samples.
- Cross-Lingual Discussions, this is a novel knowledge distillation technique that allows agents to share insights and patterns across language boundaries, leading to more comprehensive programming language understanding.
- Synergy Evaluation Metric, a newly developed metric to assess the quality of shared knowledge between programming languages with the model.
- Adaptive Instruction Generation, tries to find knowledge gaps in a given language (or multiple) and generates instructions to cover this gap.
Quality Assessment
Since the above generates synthetic data it is necessary to have a strong automated validation system, which in this case consists of the following checklist:
- Consistency, is the answer to the question correct?
- Relevance, is the question answer pair about coding?
- Difficulty, is the problem sufficiently difficult? An ideal problem is not too easy not too hard.
- Code exists, is there code inside question answer pair?
- Code correctness, does it compile, without syntax errors?
- Proper variable naming and formatting, does the code snippet follow best practices?
- Code comments, are code comments present and relevant?
- Helpful to a student, does the code carry useful information for somebody who is trying to learn?
The final quality score is just a weighted sum of the individual scores from above.
Code Verification
Let’s dive a bit more in depth into the subject of code verification. What does it mean in this context? First we use static analysis to verify if there are no syntactic errors, if this passes we generate unit tests. Unit tests should cover edge cases and are executed in isolation. Based on the unit tests we further fine-tune the code snippet.
Direct Preference Optimization
Here DPO is enough, since we get feedback from executing the code which is great since we do not need a reward model and we trained the model on the synthetic data generated from the multi-agent system. Training starts with simpler lower quality samples and we continually feed higher quality samples in later stages.
Performance
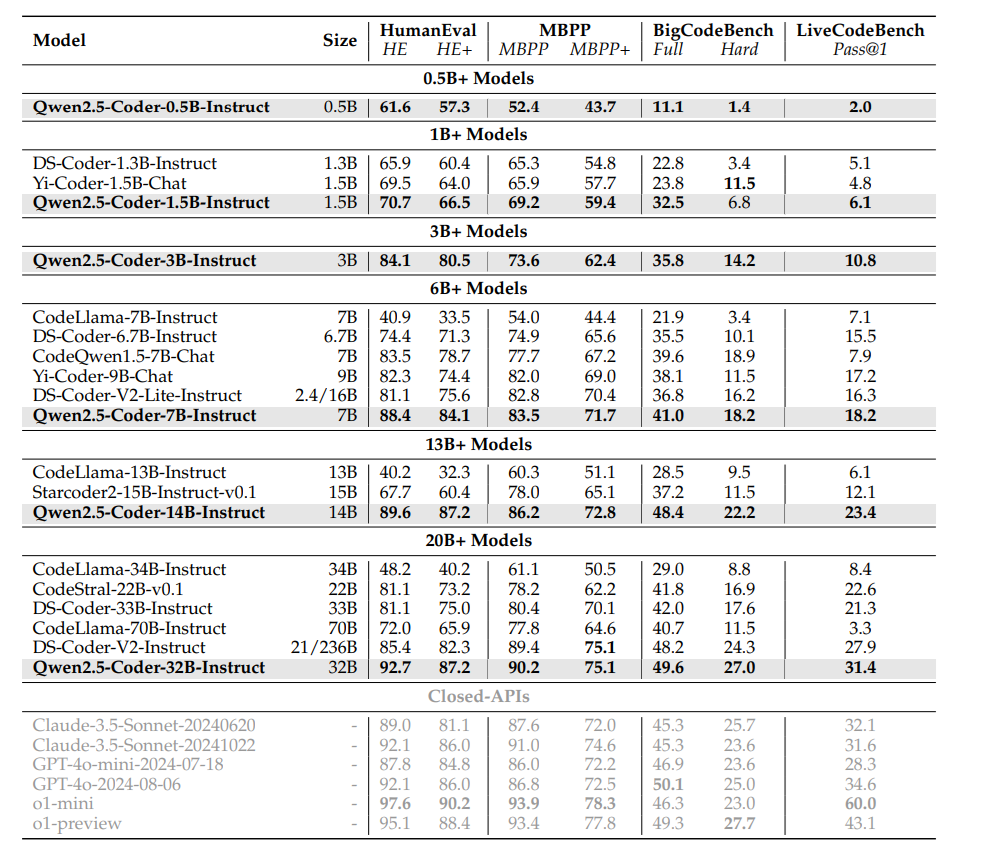
Up to the date of writing, Gwen2.5-Coder 32B is really the best open source coding model out there, especially in the league of 32B parameters (There is Codestral-25.1 that maybe could challenge it but I have serious doubts). And the thing that really stands out is that even Gwen2.5-Coder 7B is clearly better than DeepSeekCoder-32B which has 4x more parameters! Technically it also challenges the big guns like Claude Sonet and GPT4, however I take this with a grain of salt, but in terms of price performance Gwen clearly can be a super alternative for an agenting code generating system like smolagents from Hugging Face.
Knowledge Check
Loading...
Loading...
Loading...
Final Remarks
To sum it up, Gwen2.5-Coder is an amazing piece of technology, and it is a result of clever, non-trivial data synthesis. To me this paper really shows the power of AI Agents and their application for software engineering and it clearly shows that with the tooling we right now have, there is a possibility that we can build agents that will be able to build applications of medium complexity, however I do not believe that this will be without human supervision. I suspect that a lot of the user facing Front End could be automated since in most cases this is really a low risk domain, since most of the things happen in the browser which is already heavily sandboxed.