Abstract
Not long ago, I wrote about GraphCodeBERT. It builds upon the idea that source code is mostly a graph, and through a couple of clever tricks, we can embed the Data Flow into a sequence model. This approach works to some extent, however, there are drawbacks. First, since it encodes the DFG as tokens, it takes up precious space which is already very limited. Second, it modifies the attention mechanism, making it tricky to leverage state-of-the-art solutions like FlashAttention since you cannot really provide a custom mask! Third, BERT is an encoder model, which limits its application when it comes to more generic source code analysis.
GALLa is an extremely interesting approach, which combines two of my favorite techniques: Graph Neural Networks and Large Language Models. Let’s look into the details:
GALLa
The main idea behind GALLa is to take any Graph Neural Network, train it on source code, embed the learned node embeddings into any LLM (obviously open source), do a bit of fine-tuning, and we are ready to ask code-related questions.
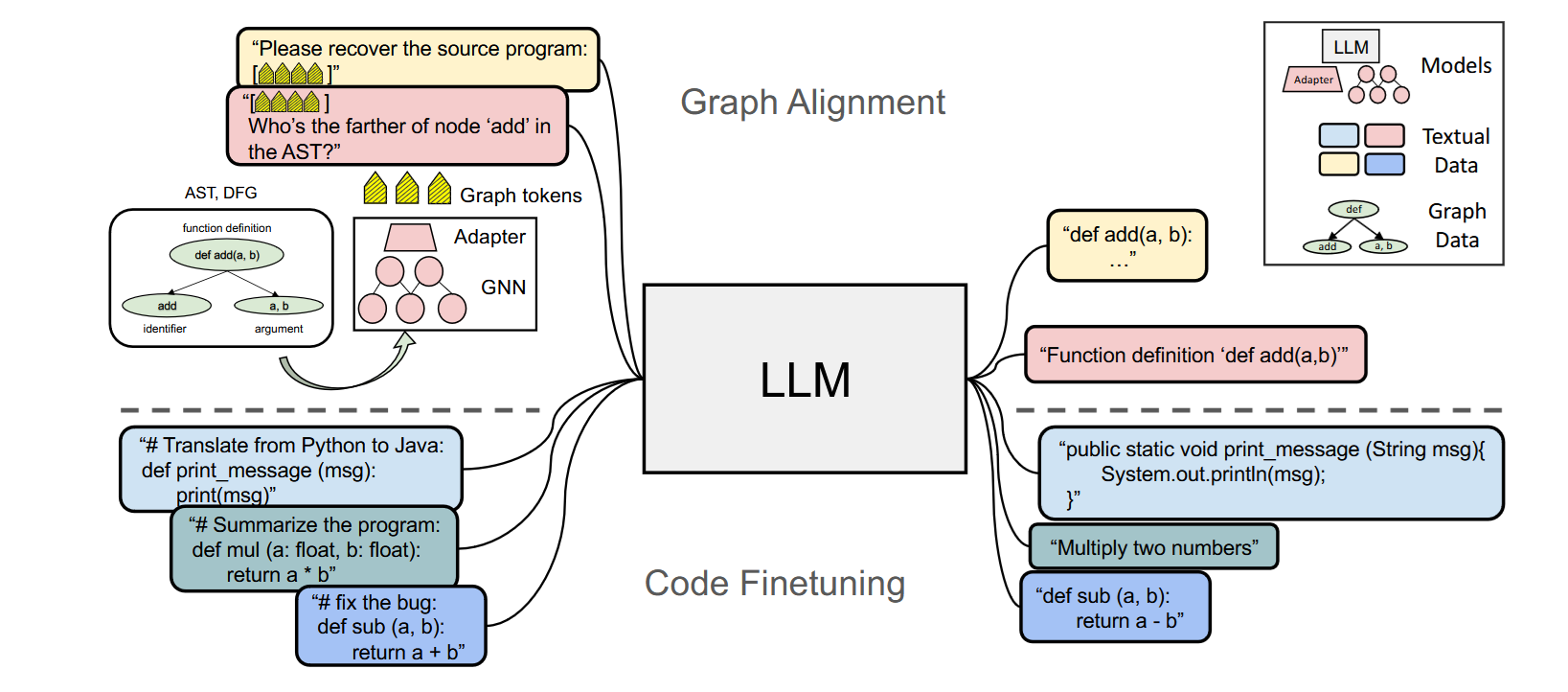
Model
We have 3 parts:
Graph Encoder
First, we need to break down a programming language snippet into a graph, this could be one of the following:
- Abstract Syntax Tree (AST)
- Control Flow Graph (CFG)
- Data Flow Graph (DFG)
Authors choose AST and DFG, and since GALLa has to be applicable to multiple programming languages, we need to generalize their representations to be language independent. Since GNNs are not that good with text, we take each node and pass it through an embedding model - this can be BERT, CodeBERT, GraphCodeBERT or CodeT5+. We end up with the following graph:
- is the vertex matrix, where each individual entry is a vector produced by an embedding model
- is the edge matrix, this was not explicitly stated but I assume that each entry is a tuple, with either 0 or 1 indicating a link between two nodes, and since these graphs are directed each tuple element encoding one direction, eg: would encode a cycle between 2 nodes , would be a path from and
For the actual model, the authors use DUPLEX, this model is amazing and I am planning to cover it more in depth in another post. For now the important parts are: 1. It is a direction-aware Graph Neural Network that leverages two specific encoders, one responsible for encoding the existence of a path between two nodes and one that encodes the direction. The model can be trained in a fully unsupervised manner on graph reconstruction, but also supports a mixed supervised objective.
The results are contextual representations for each node:
One thing that pops out is that the dimensionality of individual node embeddings is different from the embedding dimension of an LLM and we need to massage it a bit.
Graph-LLM Adapter
Adapters are not a new thing, they are a de facto standard when it comes to embedding different modalities into LLMs. For example, LLaVA uses a feed forward neural network to match the dimensions from an image encoder. For GALLa we use an alternative approach of using Cross Attention (also used by Gwen-VL).
- hidden representations of the GNN above
- is learnable
LLM Decoder
The LLM Decoder takes the aligned GNN tokens , and concatenates it with the prompt, source code snippet that we pass to the LLM.
The example above has the graph tokens always at the beginning however this is not always the case, there are special cases where we start with a prompt and follow up with graph tokens later.
Knowledge Check
Loading...
Loading...
Training
 We have multiple stages, in the first stage we train the Graph Encoder and the Adapter. For the first stage it is important to keep the LLM frozen otherwise it may degrade its performance. In the second stage we train everything as a whole.
We have multiple stages, in the first stage we train the Graph Encoder and the Adapter. For the first stage it is important to keep the LLM frozen otherwise it may degrade its performance. In the second stage we train everything as a whole.
Graph Encoder
The GNN and the adapter are randomly initialized, and trained on Graph-To-Code generation, which can be summarized as follows:
- GNN encodes the graphical representation of source code.
- LLM takes this encoded information and tries to reconstruct the original source code.
Because of that we can say we maximize the following probability distribution:
Graph-LLM Alignment
Here we unfreeze the LLM and train the model as a whole, this forces the LLM to better align its knowledge and leverage the graph at hand for output generation.
Here we have 3 different objectives:
- Graph-To-Code, this is the same as above with the distinction that we train all the weights
- GraphQA, we ask graph related questions:
- are these 2 nodes related, technically this is edge prediction
- give me the children of this node
- give me the parents of this node
- Bunch of additional downstream tasks, like:
- Clone detection, this is also known from GraphCodeBERT
- Java to Python, Python to Java translation
- and more
For efficiency reasons we can use LoRA (parameter efficient finetuning) for the LLM.
Knowledge Check
Loading...
Loading...
Experiments
The authors take a couple of popular LLMs, Duplex (7M parameters) as the GNN and they evaluate their method on the following tasks:
- Edge prediction, where we want to predict if there is an edge between two nodes. This leverages the DFG of the source code, for this task the actual AST was not really useful.
- Parent prediction, where we try to predict the parent given a node. This leverages both AST and DFG.
- Child prediction, where we try to predict the children given a node. This also leverages both AST and DFG
- Downstream tasks, these tasks are:
- clone detection
- code translation
- defect detection
- code repair
Results
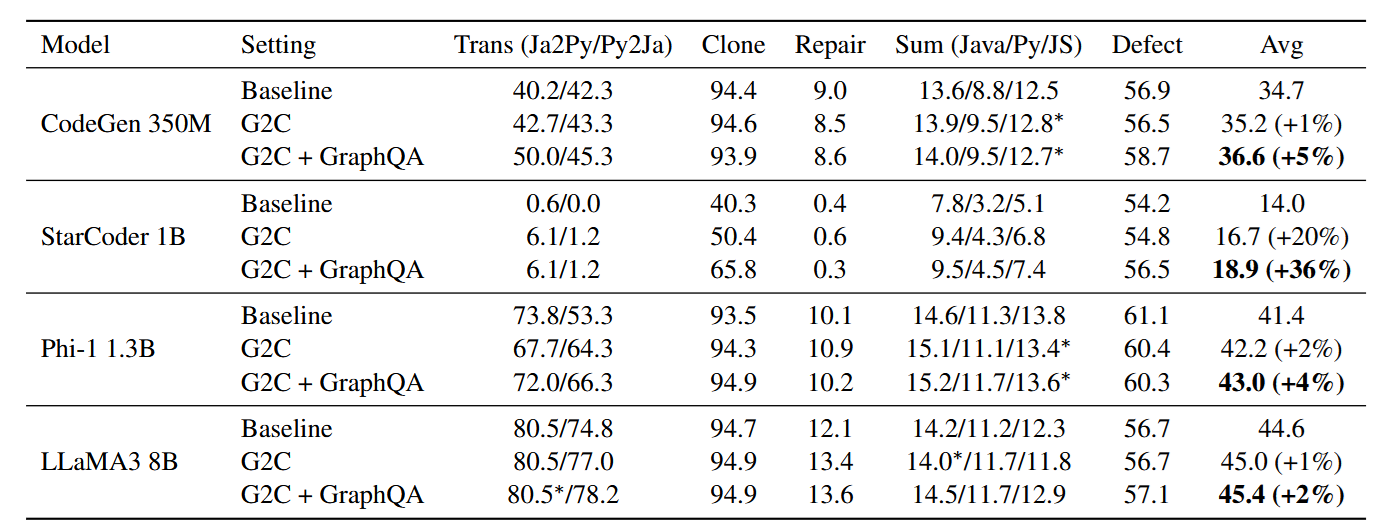
Here we can see that GALLa is indeed helpful, however the biggest gains are for small, weaker models. This is not necessarily a bad thing, and I can clearly see a specialized Small Language Model combined with a GNN can give an extremely resource efficient solution.
Recap and Final Thoughts
GALLa is an extremely interesting direction of research, and it has a lot of novelty since it is the first method that embeds GNNs inside LLMs in search for better performance on software engineering tasks. The only downside is that currently powerful models (7B+ parameters) are gaining the least benefit, however I clearly see multiple research directions like: Instead of using a local AST/DFG we can try to process the whole codebase and embed information from classes, functions or even the whole repository or even multiple repositories. I personally see a lot of similarities between the Meta tokens used by Hymba and the embedded graph in GALLa.