
Fuzz Blockers
First let’s describe how grey box binary fuzzing typically works. For example, AFL++ inserts specific compile-time instructions at the beginning/end of each basic block. These instructions are then used by the fuzzer’s harness, whose responsibility is to control the actual fuzzing process. Its goal can vary but in general it tries to maximize the number of unique visited edges between two basic blocks. We can imagine fuzzing and edge coverage as a partitioning problem, where we partition the program space into a tree (graph), where each node is represented by a basic block, and our objective is to explore this newly partitioned space as efficiently as possible with a constrained budget.
Fuzz blocker is an exception, error, bug or vulnerability that causes a fuzzer to stop and is unable to further explore the basic blocks that lie behind the problematic point.
Fuzz blockers introduce regions of code that cannot be explored and which may, and probably will contain vulnerabilities. Formally we will call these future vulnerabilities: Occluded vulnerabilities, these are vulnerabilities that are present but they cannot be triggered by a fuzzer, or at least they are extremely difficult to trigger by a fuzzer or by a user.
Why are fuzz blockers or occluded vulnerabilities even important? Let’s look at the StageFright bug!
StageFright
This was an Android bug that affected versions 2.2 up to 5.1 exposing around 950 million devices, which at that time accounted for 95% of all the devices. What makes it worse, this was a zero click bug, which means that a user was not required to do anything to be exploited, it was enough that they received a well crafted MMS message. The actual bug was inside an Android core library called libstagefright, which is used to play various multimedia formats such as MP4 files, and it contained an integer overflow bug which was exploitable.
The impact of this bug was catastrophic, but what was worse it actually introduced 10 CVEs and it took 3 weeks and more than 20 incomplete patches to fix the vulnerability. Why did it take more than 20 patches? Because each patch uncovered a future vulnerability.
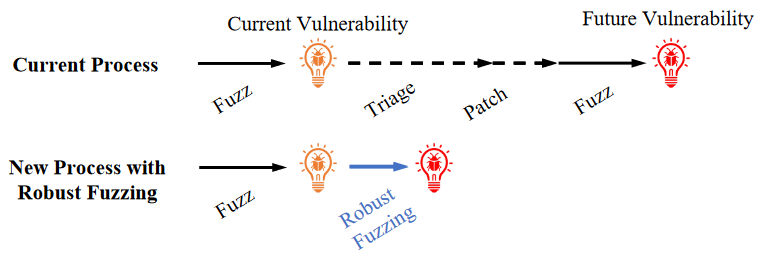
The promise of robust fuzzing is to reduce the process of finding future but existing vulnerabilities, the picture below compares the two approaches.
Knowledge Check
Robust fuzzing
To define robust fuzzing we can view it as an iterative process, where if we find a fuzz blocker, we try to automatically fix the issue, in a way that the fuzzing can continue.
Steps
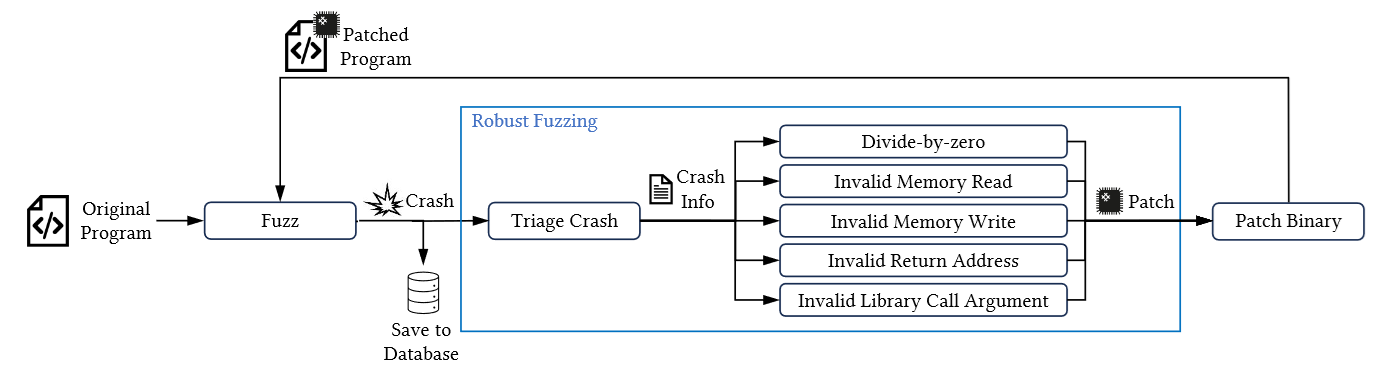
Robust fuzzing runs in a fuzz-crash-analyze-patch loop, and we can visualize it with the following image:
-
Fuzzing runs until it crashes the binary under test
- what is important here is that we need to verify if this crash is reproducible, if not we continue fuzzing until we find another crash
-
Once we have a reproducible crash, we need to determine if we can fix it
- this is done using binary patching, and we have multiple strategies we will discuss later
- if we cannot fix the crash then we return to step 1
- If we successfully patch a binary, then we can continue fuzzing with the newly patched binary
- here we requeue the input that crashed the old binary and we hope that the patch works and we can continue
Let’s look into individual steps in more depth.
Crash Verification
To verify if the crash is valid we first need to be able to reproduce it, if for some reason we fail then we throw the crash away as a false positive. If we manage to reproduce it, then we retrieve the memory mapping of the program. From this memory mapping we can determine where the crash has happened, this involves a static memory location, the callstack and values of registers. This information can help us to determine what issue caused the crash and if we can fix it. Again if we fail to retrieve the memory mapping, or if we fail to determine the cause of the crash then we just ignore it, since we cannot patch it.
Patch generation
Here we perform binary patching, which is a technique where we overwrite, or in our case also include additional, bytes. These extra bytes modify the instructions that are executed, and they are tailored to circumvent a crash.
The actual patch generation consists of 3 components:
-
Entry, this is the entry point of the patch, most of the time it is before a problematic instruction, or a couple of problematic instructions. In this component we analyze the current program state, (stack, registers, …) and we save this program state so we can restore it later to redo any changes introduced by our patch.
-
Crash Preventer, once we know what causes the crash we can run the crash preventer, which applies the minimal modification to the binary to prevent the crash.
-
Exit, this component is executed after the Crash preventer applied its patch, and its role is to restore the program state saved in the Entry component. This is necessary since during Crash Prevention we may modify register, stack or heap and we need to undo these changes otherwise we would interrupt the remaining control or data flow of the binary.
Patching Strategy
As discussed in the Crash Prevention component, we apply a minimal change to prevent a crash. This minimal change does not and probably will not be 100% correct, however it turns out it does not need to be correct. All we need is a semantically valid patch, that enables the fuzzer to continue.
As for the actual patch, the authors propose different patches for different errors instead of a generic patch that could be applicable to any error. This makes the individual patch smaller and the system is easier to extend, but it requires a comprehensive crash identification.
False Positives
Since we approximately patch binaries, we may actually introduce false positives, that means bugs that are not really in the binary but are introduced by our patch. In contrast to traditional fuzzing which cannot introduce false positives this is somewhat a negative and may require in-depth analysis of occluded bugs, but that is needed anyway!
Exploitability
The big question is, can we exploit occluded vulnerabilities? Well not really. They are hidden behind bugs that cannot be circumvented in normal control flow. However it does not mean that they are harmless, an adversary could provide valid patches for fuzz blockers and later exploit the remaining vulnerabilities.
Knowledge Check
FlackJack
The authors built an experimental robust fuzzing tool they coined FlackJack and it builds on top of AFL++ and uses PatchRex (this is from the amazing Angr and pwncollege team which are also the authors of the paper). FlackJack is able to detect and automatically patch the following subset of errors:
1. Divide by Zero
For divide by zero the register that is zero is initialized to a random integer.
2. Seg fault during memory read
Let’s look at the following example instruction:
movzx eax, word [rax+rcx*2]
We read to a memory region that is not valid, this means register rax points to a location that is invalid. To fix this we take one guaranteed valid memory address, and replace rax to this address. The guaranteed memory address is taken by performing static analysis on the source code before fuzzing.
3. Seg fault during memory write
The problem is analogous to memory read segmentation fault, here is the example instruction:
mov dword [rdx+rcx*4],eax
In the example above rdx points, similarly as by reading, to an invalid memory location. To fix the issue we choose a random area that we know is writable.
4. Invalid return address
Invalid return address is an indication of stack smashing (stack buffer overflows). By default this address is at rbp+8 given a function’s call stack, that is set up during the prolog. The patching approach is to insert extra instruction that takes rbp+8 and stores it in a static location that won’t be changed, and restore it before the ret instruction.
5. Invalid library call argument
For library functions, we patch only the passed arguments, and not the actual code. The types of functions we can patch are limited to:
- take one argument that is a pointer (strlen, strchr, …)
- take two arguments each a pointer (memcpy, memmove, memcmp, …)
Similar to memory segmentations we set these points to valid memory locations either to a valid memory address determined by static analysis or by leveraging the madvise syscall.
Experiments
The authors did benchmarking on FlackJack to determine its efficiency. This was done on older binaries, that are known to have vulnerabilities, but they are already patched. The idea is that FlackJack should be able to patch these binaries and potentially find new vulnerabilities that are occluded.
Patching Success
During their fuzzing run they patched 7582 crashes out of 8093 crashes, which means the patching success was around 93%.
Finding Bugs!
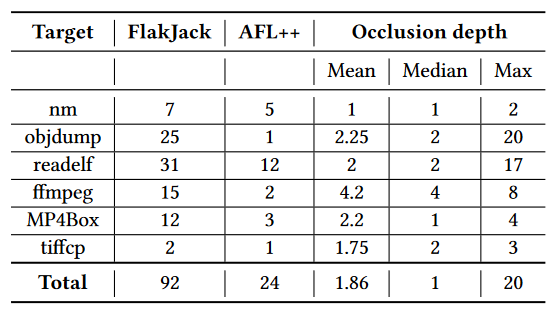
From the image above, we can already see, that FlackJack is able to find more vulnerabilities than plain AFL++. We can also see that occluded vulnerabilities are well hidden and we need to bypass at least 2 unique crashes to find a new one.
Recap
Robust fuzzing gives security researchers a great tool to reduce the time it takes to uncover software vulnerabilities. The authors provided nice research on how a minimal semantically valid binary patch can resolve fuzz blockers and enable the fuzzer to better explore the program space. Unfortunately right now FlackJack, their implementation of robust fuzzing is not really available to the public, but that is not surprising given the relative freshness of the research.