
Fuzzing
Fuzzing is a common technique that throws random input at a System Under Test (SUT), a fancy name for a program, trying to force it into some unexpected behavior. This unexpected behavior can include bugs or corner cases the developers of the SUT did not think about. Some of these bugs can be security vulnerabilities. For example, SEGFAULTS are memory-related bugs that occur when a program tries to access memory it is not allowed to, and they can happen during Stack Buffer Overflow attacks, where we overwrite the return address of a function to a memory area that does not belong to the program. For the purpose of this article, I briefly introduce two fuzzing techniques: Generation Based Fuzzers and Mutation Based Fuzzers.
Generation Based Fuzzers
Generation based fuzzers are used to generate standalone pieces of code that can be interpreted or executed. For example, CSMIT is a fuzzer that generates C code, while SyzKaller generates syscalls for the Linux Kernel. These fuzzers are based on predefined grammars, templates, and rules that are used to generate and modify code. There are a couple of disadvantages to these types of fuzzers:
- Tight coupling to a specific language or domain For example, CSMITH is an 80K line C++ program that generates C code, which can be used to test C compilers. SyzKaller has tens of thousands of rules on how to generate and modify syscalls. Building such a fuzzer is a huge effort, and they are hard, in most cases impossible, to reuse for other languages or domains.
- Limited expressiveness of the grammar or templates Since we have strict rules on how to generate and change code, this ensures the validity of their output, but often they fail to efficiently cover the whole language or domain.
- They lag behind the development of the SUT If a language or domain changes, for example by introducing new language features or system calls, the fuzzer needs to be adapted to these changes. This is a huge effort, and because of that, most fuzzers often do not support the latest features, sometimes lagging behind for years.
Mutation Based Fuzzers
A couple of examples of Mutation/Evolution fuzzers are LibFuzzer and AFL (the latter is archived, however still heavily referenced in a lot of papers, and there is a fork called AFL++). The main idea behind evolution fuzzers is that they throw random byte sequences at programs and see how they behave. Then they evolve the input based on some sort of fitness function (system crash or coverage) to generate new inputs. This is done by mutating the input, for example by flipping a bit, adding or removing bytes, or changing the order of bytes.
Pros
- They are language agnostic and can be used with any system that takes bytes as input.
- They can be used to test the behavior of the whole SUT, not just a part of it.
Cons
- They are not very efficient, since they have no idea about the underlying structure of the input, nor about the SUT itself.
- They are not very good at generating complex inputs, since they are based on random mutations.
Fuzz4All
Fuzz4All is a Generation Based Fuzzer that leverages Large Language Models (LLM) to generate code for the underlying SUT. By using LLMs to generate code, we circumvent the biggest weakpoints of traditional generation based fuzzers by:
- Making it language agnostic
- Providing additional information in prompts, enabling it to adapt to changes in the SUT and to new features that the LLM was not trained on
- Generating more complex code snippets supporting the whole language or domain
Model
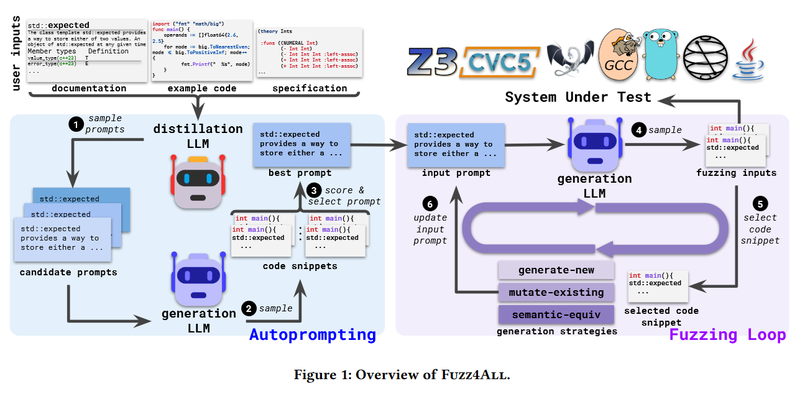
The model consists of two main parts: Autoprompting and Fuzzing Loop.
Auto Prompting
Since the user can provide a lot of information in the prompt, like code snippets, documentation, or other natural language information to guide the fuzzing process, this information can contain duplicates or unnecessary details. To reduce the input, we use a High Quality LLM (GPT4) to distill the provided information into a summary. The distillation is done first with low temperature to ensure that we get output that is highly plausible, then we continue with higher temperature to get more diversity.
Once we have distilled the input, we provide it to a cheaper Generation LLM (StarCoder). The role of the generation LLM is to generate candidate code snippets. These code snippets are then ranked based on a scoring function (validity of the code snippet) and we choose the prompt that has the highest scored code snippet.
Fuzzing Loop
Once we have our initial prompt, we refine it in a loop, generating code snippets using the Generation LLM, using the following 3 strategies:
- We generate a new code snippet.
- Mutate the existing code snippet; here we provide the original code snippet as an example to the generation LLM to guide it to produce similar variants.
- Generate a semantically equivalent code snippet; again, we provide the original code snippet as an example to the generation LLM to guide it to produce similar variants.
Each time we choose one of the above strategies at random, except for the first iteration when we always generate a new code snippet.
Results
We compare Fuzz4All with other industry standard fuzzers for a given SUT, with a fuzzing budget of 24 hours.
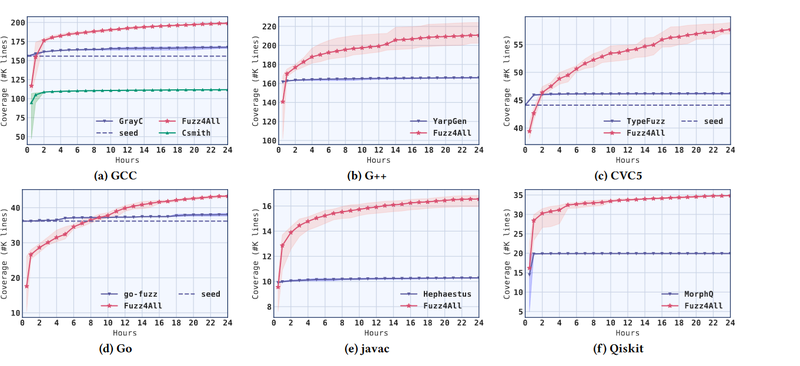
Fuzz4All improves the coverage compared to other approaches. However, at the beginning, the coverage is lower, but it steadily improves until it surpasses others, even showing a trend to improve the coverage at the boundary of its budget. Overall, we have a 75.6% improvement in coverage compared to other approaches.
Validity
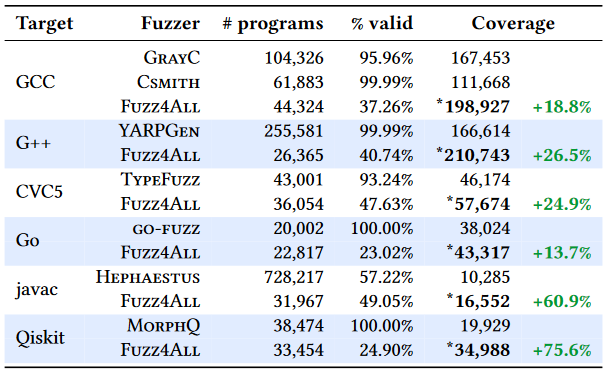
Since we leverage LLMs to generate code snippets, we tend to produce fewer valid code snippets compared to traditional generation based fuzzers. This results in a lower number of valid programs generated. However, since we are able to cover a bigger portion of the SUT, we have higher chances of finding bugs.
Targeted Fuzzing
Since we can provide natural language prompts, we can target specific functionality of the SUT. This allows us to target specific features of the underlying SUT. For example, if we are testing a C compiler, we may ask it to specifically target “goto” statements; for Go programs, we may ask it to target “atomic” or “defer” statements. Targeted fuzzing is an approach that is not available to traditional approaches.
Bug Finding
The authors managed to find 94 bugs across 6 different SUTs (GCC, G++, Go, javac, CVC5 (an SMT solver) and Qiskit (a quantum computing library on top of Python)). Of the 94 bugs, 64 were previously unknown and also confirmed by the developers as bugs.
Remarks
This is an extremely promising approach; however, it is not without flaws. It relies on the fact that the Distillation LLM and Generation LLM have seen the SUT during pretraining. This assumption may not be true for commercial systems, limiting its commercial viability.
FuzzCoder
FuzzCoder is an approach that again leverages LLMs but to perform Mutation based fuzzing. The LLM takes a byte sequence as input and outputs a sequence of mutations. These mutations are then applied to the input to generate new inputs. Since it is not really straightforward how to prompt the model to perform these mutations, the authors performed supervised fine-tuning of the underlying LLM(s).
Model
The input of the model is a sequence of bytes and the output is a sequence of tuples , where: are mutation positions and are mutation strategies.
Possible Mutation Strategies
Here is the list of possible mutation strategies:
- bitflip 1/1: perform bitflip on a bit randomly.
- bitflip 2/1: perform bitflip on two neighboring bits randomly.
- bitflip 4/1: perform bitflip on four neighboring bits randomly.
- bitflip 8/8: randomly select a byte and XOR it with 0xff.
- bitflip 16/8: randomly select two neighboring bytes and XOR them with 0xff.
- bitflip 32/8: randomly select four neighboring bytes and XOR them with 0xff.
- arith 8/8: randomly select a byte and perform addition or subtraction on it (operands are 0x01 0x23).
- arith 16/8: randomly select two neighboring bytes and convert these two bytes into a decimal number. Select whether to swap the positions of these two bytes. Perform addition or subtraction on it (operands are 1 35). Finally, convert this number to 2 bytes and put it back to its original position.
- arith 32/8: randomly select four neighboring bytes. Select whether to swap the positions of these four bytes. Convert these four bytes into a decimal number. Perform addition or subtraction on it. Finally, convert this number to 4 bytes and put it back to its original position.
- interest 8/8: randomly select a byte and replace it with a random byte.
- interest 16/8: randomly select two neighboring bytes and replace them with two random bytes.
- interest 32/8: randomly select four neighboring bytes and replace them with four random bytes.
LLMs
The authors fine-tuned the following LLMs:
- StarCoder-2
- Code-Llama
- DeepSeek-Coder
- CodeQWEN the 7B model
Fine-tuning
This is done by collecting successful fuzzing history consisting of original input and mutated input. Successful means that the program crashed or triggered a new execution path. Unfortunately, the paper does not go into detail on what the fuzzing targets were. Here I can only hope they were different from the test programs.
Prompt
The prompt looks like this:
Task Description:
Now, you are an AFL (American Fuzzy Lop), which is a
highly efficient and widely used fuzz testing tool designed
for finding security vulnerabilities and bugs in software. You
are now fuzzing a program named {dataset_name}, which
requires a variable (a byte sequence) to run. I will give you a
byte sequence as input sequence, and you need to mutate the
input sequence to give me an output sequence through a
mutation operation below. Finally, you need to give me an
output which includes input sequence, mutation operation,
and output sequence.
Mutation Operations:
{Mutation Operations 𝑂}
Input Sequence Definition:
It consists of bytes represented in hexadecimal, separated by
spaces. It is the byte sequence to be mutated. It is a variable
that can cause the program to crash or trigger a new path.
Output Sequence Definition:
It consists of bytes represented in hexadecimal, separated by
spaces. It is the mutated byte sequence. It is a variable that
can cause the program to crash or trigger a new path.
Input Sequence:
{byte_input}
Please list all possible mutation strategies (mutation position
and mutation operation) with the JSON format as:
output:
{
"mutation strategies": [
(𝑜!, 𝑝!),
... ,
(𝑜", 𝑝"),
]
}
Here I assume that {dataset_name} is the name of the SUT.
Results
FuzzCoder was tested against the following programs:
- nm-new
- readelf
- objdump
- xmllint
- mp3gain
- magic (GIF)
- tiffsplit
- jpegtran
Crashes
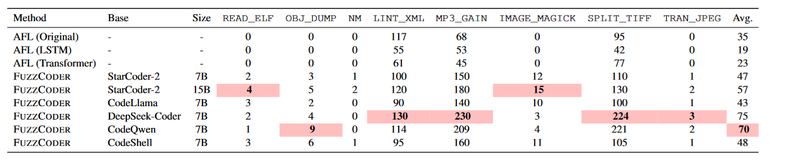
We can see that LLMs trigger the most crashes. There are a couple of baselines involved: AFL is just AFL, LSTM and Transformer (encoder-decoder) were not pretrained (It is not explicitly stated, but I assume that they were trained on the Fine-tuning Mutation Dataset, otherwise they would just generate random mutations).
Coverage
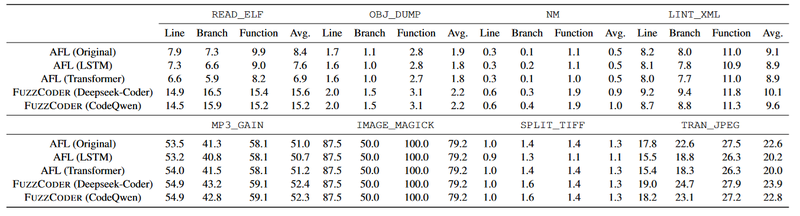
Leveraging LLMs increases the coverage ratio (times they have been executed) of lines, branches, and functions, with a clear increase in the complete paths for line and branch coverage.
Remarks
FuzzCoder is a promising approach, but it inherits the flaws of Fuzz4All: it assumes that the language model has seen the program during pretraining, which is unreasonable for any closed-source project. The research has a big gap; it is unknown what programs were used to create the pretraining data.
Remarks
Mutation-based fuzzing is a battle-tested approach; projects like OSS-FUZZ have uncovered numerous bugs in open-source projects. Leveraging the power of pretrained LLMs that know the source code of the project and have seen numerous inputs for generating better seeds or even doing the whole mutation is a direction worth exploring. Similarly, leveraging LLMs to generate code snippets instead of hand-crafted Generation-based Fuzzers is a great approach to test functionality of open-source libraries or systems that take some sort of formal language as input.
The biggest downside of both approaches is their assumption that the LLM has already seen the SUT, which is not the case for any closed-source project, limiting the commercial viability of the approach. However, it opens up a lot of possibilities for Open Source LLMs that can be pretrained on in-house codebases, or combining them with Retrieval Augmented Generation (RAG) (technically we can do this even with closed-source LLMs; however, then we are sending our code to the cloud, which we may not want, although with coding assistants we already do that for some time now) to teach the LLM about the SUT.