Abstract
A lot of more advanced Machine Learning Models for Source Code Vulnerability analysis utilizes CodeBERT or GraphCodeBERT at one form or the other. Having an solid foundation how BERT works is crucial to understand how it can be extended to better suit our needs.
BERT
Introduces by devlin2019bert it is a Transformer model, designed to process natural language text.
Transformer
We won’t get into the nuts and bolts of the Transformer model here, but to put us on the same page we need cover some essential components
Self Attention
Mathematically, attention is a weighted average. For each token in the input sequence, we compute its contextual representation (Some Vector) by considering itself and other tokens, weighted based on their relevance. In self-attention, we only use the input sequence itself.
Multi Head Attetion
This applies self-attention multiple times in parallel, allowing the model to learn different relationships between tokens.
Feed Forward Network
This network is used at multiple points to introduce non-linearity and enable the model to learn complex relationships between tokens.
Layer Normalization and Residual Connections
These techniques help with gradient descent optimization. Layer normalization ensures the gradients don’t become too large, while residual connections allow later parts of the model to access the original input for a given layer (not the raw tokens).
A bit more!
If you ever read a bit more indept into Transformers you will encounter terms like Tokenizer, Embeddings, Prositional Embeddings and Softmax.
- Tokenizer take an input string and produces a sequence of tokens. A token is just an integer, and depending on the implementation it a single word may be split up into multiple tokens.
- “Embeddings” (Just Embeddings) take every input token and they transform it in a vector (just a buch of floating point numbers).
- Positional Embeddings encode the position of the token in the input string by adding some information to its Embedding (From above!). Why is this needed? Well I said that self attention is just a weighted sum, and as you know from mathematics if you compute the sum (weighted or not) the result will be the same no matter in what order you do the summing up.
- Sofmax, is a function that takes an input sequence of numbers and it will normalize it that they sum up to 1 and each one of them is greater (or equal for negative infinity) to zero.
TLDR;
This may frightning (or not, depending how deep are you in these topics), what you need to take with you is that:
Transformers are a technique centered around Multi Head Self Attention with is just a weighted average, where we use the input itself to compute the weights, we do it multiple times for the same input to capture the importance for different parts of the same input, and since we do not want to loose the information what is where we use Positional Embeddings. By using (Feed forward) neural networks we are able to capture complex interactions between different parts of the input.
The input in general is just a string, well Machine Learning kind of suck at working with string, we transform strings into a sequence of integers, having a single integer for a word (or part of a word) is kind of limiting so we take a sequence of integers and we transform them into a sequence of vectors.
To train the model we use a (Gradient Based) Optimizer, and to make sure the learning is stable we use Layer Normalization and Residual Connections. By using Residual Connections we also enable the model to have access to the original input for a given layer.
Knowledge Check
Loading...
Loading...
Model
We’ve established that BERT is a Transformer model composed of multiple Transformer blocks, each built using the components described earlier. However, there are key differences between BERT and other recently more popular models like (Chat)GPT.
Causal vs. Bidirectional:
- GPT (Generative Pre-trained Transformer): This is a causal decoder-only language model. It excels at predicting the next token based on the previous tokens
- BERT (Bidirectional Encoder Representations from Transformers): In contrast, BERT is an encoder-only model, also known as a bidirectional Transformer model. When applying a Transformer block to the input (potentially from a previous layer), BERT obtains a contextual representation for every token embedding. This means it can consider all tokens in the input sequence to compute the contextual representation for a single token. Unlike GPT, BERT is not limited to using only the preceding tokens.
Contextual Representations
This emphasis on contextual representations is crucial. We’ll leverage these representations for various tasks, sometimes even forcing them to take specific forms. For instance, in classification tasks, we utilize the contextual representation of a special token called [CLS], which always occupies the first position in the input sequence. We’ll explore other special tokens in the Pretraining section.
Model Reference
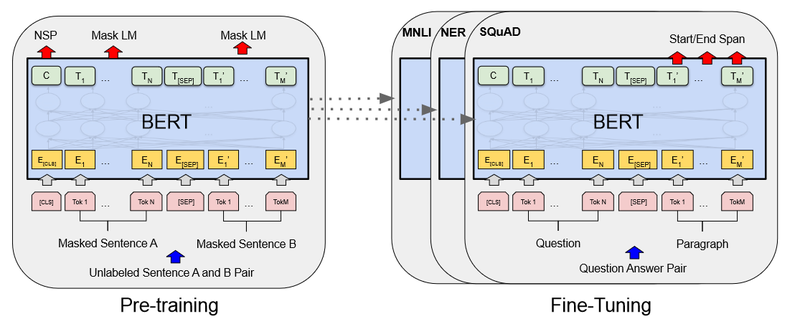
Pre-training
Pre-training is a technique where a large dataset is used to train a model, which is then fine-tuned on a smaller, more specific dataset. This allows the model to learn general features of the data and then be adapted to a particular task. It’s a common approach in machine learning and used for various models.
The overall goal of pre-training in BERT is to predict masked tokens within a sentence. To select which tokens to mask we take a random sample (around 15%) of the input tokens and transform them in three ways:
- 80% Masked ([MASK]) Token: These tokens are replaced with a special “[MASK]” token, forcing the model to predict the original content.
- 10% Random Token: These tokens are replaced with a random token from the vocabulary, introducing noise and improving the model’s robustness.
- 10% Original Token: These tokens remain unchanged, as there won’t be any masked tokens during fine-tuning.
The pretraining objectives are:
- Masked Language Modeling (MLM): The model is then trained to predict the original tokens for the masked positions,. We achieve this by:
- Taking the output from the final Transformer block.
- Applying a linear transformation to this output, resulting in a vector with dimensionality equal to the vocabulary size (one dimension for each possible token).
- Applying a softmax function to this vector, generating a probability distribution over all possible tokens in the vocabulary.
- Using optimization algorithms to maximize the probability of the original tokens being predicted correctly.
- Next Sentence Prediction (NSP): We introduce another objective: predicting the relationship between two sentences. This involves a second special token, “[SEP]”, used as a separator between sentences. These sentences can be viewed as question-answer pairs, natural language descriptions paired with programming code, or any other relevant combination.
The training data consists of pairs of sentences (A and B). In 50% of the cases, B is the actual next sentence following A. In the remaining cases, B is a random sentence. To learn the relationship, we formulate the problem as a binary classification task. We use the contextual representation of the [CLS] token for this classification, determining if the second sentence follows the first logically
Knowledge Check
Loading...
Loading...
Fine-tuning
While reconstructing the original input might seem sufficient, BERT’s true power lies in leveraging the contextual representations it generates. In most cases, we utilize the representation of the “[CLS]” token for various downstream tasks, such as classification or regression.
Question answering requires a slightly more intricate approach. We provide the model with context and a question, and the model predicts the answer’s starting and ending positions within the context. To achieve this, we introduce special tokens: and . During fine-tuning, the model learns to predict the correct positions for these tokens, effectively highlighting the answer.
Text generation is a bit more complicated, we can technically add an [MASK] token at the end of the input and we can ask the model to predict the token, and repeat this by feeding the input back to the model with an additional masked token, however this will not work very well, overall BERT strougles to to produce coherent text. The reason is that the model is trained to predict the original token, and it is not trained to generate new tokens. This is a fundamental difference between BERT and GPT, where GPT is trained to generate new tokens.
Pros and Cons
Strengths:
- Bidirectional Encoding: BERT’s ability to analyze tokens from both left and right contexts allows it to capture more complex relationships between words compared to models like GPT, which are limited to the previous tokens.
- Parallelization: The computations for contextual representations can be performed in parallel, making BERT potentially faster for certain tasks.
- Efficient Downstream Tasks: For classification or regression tasks, BERT only requires the contextual representation of the [CLS] token, which can be computed efficiently.
Weaknesses:
- Fine-tuning Complexity: Introducing task-specific layers on top of the contextual representations can be complex and require additional training data.
- Limited Text Generation: BERT struggles with generating new text due to its focus on predicting existing tokens within a context. This can be a disadvantage for tasks requiring creative text productio
TLDR;
There was a lot to digest, but its main selling point is that it can capture complex relationships between tokens in the input (More complex than GPT), and we can use this representations for various tasks. However it is not suited for generative tasks!
CodeBERT
CodeBERT, introduced by Hou et al. (2020) aims to bridge the gap between natural language processing (NLP) and programming languages. This model is evaluated on various tasks, including:
- Natural Language Programming Language Probing: Does CodeBERT understand the underlying semantics of programming languages through probing tasks?
- Code Documentation Generation: Can CodeBERT automatically generate code documentation from natural language descriptions?
- Generalization to Unseen Programming Languages: How well does CodeBERT perform on programming languages it hasn’t been trained on?
Model Input
Similar to BERT, CodeBERT utilizes special tokens to structure its input:
- [CLS]: This token marks the beginning of the input sequence.
- [SEP]: This token separates the natural language description and the programming code.
- [EOS]: This token marks the end of the code sequence.
The input format can be represented as:
- is a token from the natural language description
- is a token from the programming code
Pre-training
CodeBERT leverages two pre-training strategies due to the multimodal nature of its data:
- Masked Language Modeling (MLM): This strategy, familiar from BERT, is applied only to the natural language-programming language (NL-PL) data pairs. Similar to BERT, the model predicts masked tokens within the natural language descriptions.
- Replaced Token Detection (RTD): This strategy is applied to both the bimodal NL-PL data and the unimodal programming language (PL) data. Here, the model encounters tokens replaced with plausible alternatives generated by two separate models:
- : This model generates replacements for tokens in the natural language portion.
- : This model generates replacements for tokens in the code portion.
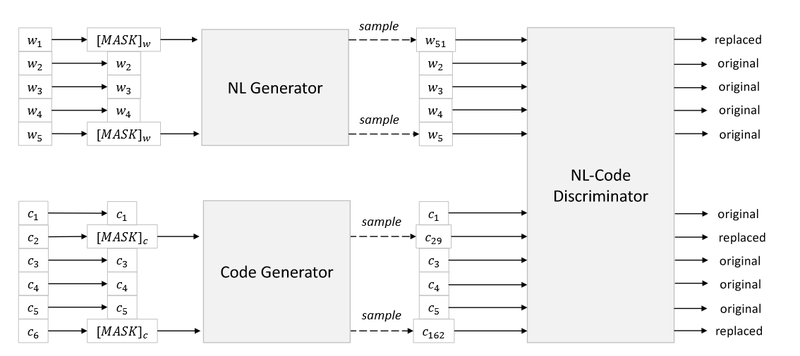
The inspiration behind RTD comes from a “de-obfuscation” task, where the goal is to identify the original name for a variable, function, or class. Understanding these names is crucial for code comprehension. However, RTD is not limited to variables; it can also replace keywords from the natural language descriptions. Overall, this strategy aims to force the model to learn the relationships between variables,
Fine-Tuning
Here, we explore CodeBERT’s capabilities in several tasks:
- Natural Language Code Search: Given a natural language query, the model aims to retrieve a relevant code snippet from the CodeSearchNet corpus. This is achieved by training a binary classifier that leverages the [CLS] token representation to determine if a given query and code snippet are related.
- NL-PL Probing: This task assesses the model’s understanding of programming and natural language. It involves predicting the correct masked token (either programming language (PL) or natural language (NL)) from a set of choices. On the NL side, keywords like “max,” “maximize,” “min,” “minimize,” “less,” and “greater” are grouped into four options. For the PL side, keywords containing “max” and “min” are replaced, formulating the task as a two-choice problem.
- Code Documentation Generation: In this task, the model takes a code snippet as input and generates natural language describing its functionality. However, similar to BERT, CodeBERT might struggle with generating entirely new text, potentially resulting in incoherent descriptions.
- Generalization to Unseen Programming Languages: Similar to code documentation generation, this task challenges the model to produce a summary in natural language for a C# code snippet, even though C# wasn’t included in the pre-training data.
Remarks
CodeBERT has become a widely used tool in source code vulnerability analysis and serves as a strong foundation for further development of more advanced models.
TLDR;
CodeBERT builds upon BERT by incorporating both natural and programming language data during pre-training. This pre-training involves two objectives: Masked Language Modeling (similar to BERT) and Replaced Token Detection (RTD), which helps the model learn relationships between variables, functions, classes, and keywords.
Knowledge Check
Loading...
Loading...
GraphCodeBERT
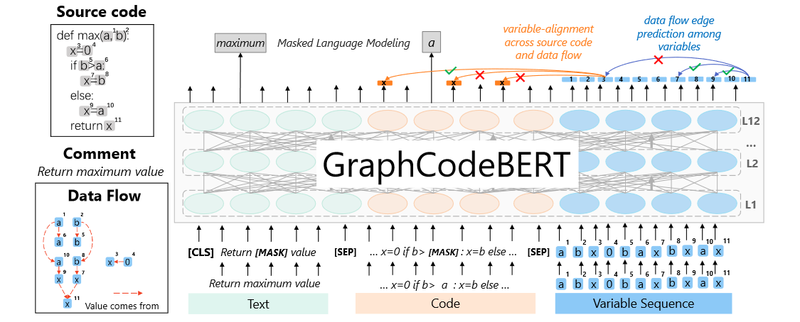
GraphCodeBERT by Guo et al. (2021) builds upon CodeBERT by incorporating information from the code snippets’ Abstract Syntax Tree (AST). Specifically, it extracts data flow between variables and trains the model to learn these relationships. This approach focuses on “where-the-data-comes-from” instead of capturing the entire AST hierarchy, providing sufficient semantic information without unnecessary complexity, making the model easier to train.
Input/Output Representations
Similar to CodeBERT, GraphCodeBERT utilizes multiple inputs:
- PL Code Snippets
- NL setence comments associated with the code snippets (akin to function documentation). From the PL code, a Data Flow Graph is constructed. represents the variables, and represents the edges, with indicating data flow from to .
The actual input is:
Architecture
GraphCodeBERT adopts the same architecture as BERT and CodeBERT, with the sole addition of a special Graph Guided Attention mechanism.
Graph Guided Attention
Previously introduced Self Attention calculates a weighted average. Graph Guided Attention is an extension that forces specific weights to zero. This is achieved by masking relationships between tokens. Masking a relationship between a PL token () and a Data Flow Graph token () assigns negative infinity to the attention score. Similarly, masking the relationship between two variables ( and ) in the Data Flow Graph accomplishes the same. By introducing negative infinity, the softmax function produces a weight of zero for the masked relationship.
Pre-training Objectives
-
Masked Language Modeling (MLM): This is the “same old” objective inherited from previous models. It involves masking random code tokens and training the model to predict the masked tokens based on the surrounding context. This helps the model learn general-purpose code representations.
-
Edge Prediction: This objective focuses on teaching the model to understand the relationships between variables in the Data Flow graph. Here’s a breakdown:
- Process: We randomly select 20% of the nodes (variables) from VV. Then, we mask the direct edges connecting these chosen nodes by adding negative infinity to their attention scores. This effectively prevents the model from considering these edges during attention calculations.
- Learning: The model predicts the probability () of a connection between node and node . This prediction is calculated by taking the dot product of the contextual representations of and , followed by passing the result through a sigmoid function. The intuition behind this is:
- High positive dot product: The vectors for connected nodes tend to point in similar directions, resulting in a high positive value.
- Low dot product: Vectors for unconnected nodes might point in opposite directions or be orthogonal, leading to a low value close to zero.
- Sigmoid Function: This function transforms the dot product into a probability score between 0 (unlikely) and 1 (highly likely). Since connected nodes should have a high probability, the model is encouraged to learn contextual representations that align for connected variables.
-
Node Alignment:
- This objective is similar to Edge Prediction, but it focuses on learning the connection between code tokens and Data Flow graph variables. The process is analogous: We mask the connections between a subset of code tokens and their corresponding variables in the Data Flow graph.
- The model predicts the probability of a connection between a code token and a variable based on their contextual representations and the sigmoid function.
- This approach encourages the model to learn alignments between code and the underlying data flow, improving its understanding of how code operates.
Fine-tuning
GraphCodeBERT is fine-tuned for various tasks:
- Natural Language Code Search: Similar to CodeBERT, this task retrieves relevant code snippets based on a natural language query.
- Code Clone Detection: This task identifies similar or identical code fragments across different parts of the codebase.
- Code Translation: This task translates code between programming languages (e.g., Java to C#). While GraphCodeBERT achieves good results, it still faces challenges in text generation common to BERT-based models.
Knowledge Check
Loading...
Loading...
TL;DR
Summary
CodeBERT is one of the most widely used language models used for vulnerability detection in source code Zhou et. al (2024). However to understand CodeBERT we first needed to grasp the power of BERT and how it generates a contextual representations of input. CodeBERT takes BERT and incorporates source code information, the contextual representation than captures relationships between variables, functions, classes, and the code’s natural language description. GraphCodeBERT takes this a step further by leveraging AST information to explicitly train the model on variable relationships.